7 Web Scraping
Goals
- Understand how HTTP works in the browser context.
- Introduce some key concepts from HTML that’ll be important for web scraping.
- Note: If you are completely unfamiliar with HTML, the resources under Further Exploration > HTML may be useful as a primer.
- Explore tools for writing web scrapers in Python.
- Discuss practical considerations that relate to writing web scrapers against real world websites.
APIs let us request data in pre-structured formats, which we refer to as machine-readable.
But most data on the web is in HTML, a markup language that (along with CSS and JavaScript) controls what you see in your browser. While technically HTML is machine-readable is not a “data format” because the primary purpose is to control presentation, not make the data accessible via code.
When we want to extract data from the HTML, we write what is often called a web scraper.
A web-scraper that visits every page on the site, often to build a search index, is called a crawler.
Before we begin extracting information from HTML it’ll be helpful to examine what a web browser does and the structure of HTML documents.
What does the browser do when it visits a page?
A browser makes HTTP requests, and then renders the resulting HTML to the screen.
We saw that HTTP is one message, one response.
But a typical web page contains references to other resources, such as:
- additional code (CSS & JavaScript)
- media files (images, audio, video)
- external data (JSON, CSV, etc.)
When the browser receives HTML, it will see these references such as:
<style src="style.css" />
<img src="logo.png" />
<script type="text/javascript" src="tracking.js"></script>Which will in turn result in additional requests before the page can render:
Note that in practice many of these requests can often happen in parallel, providing some speed benefits.
If you open your browser’s Developer Tools and then navigate to the Network tab, you can see this in action.
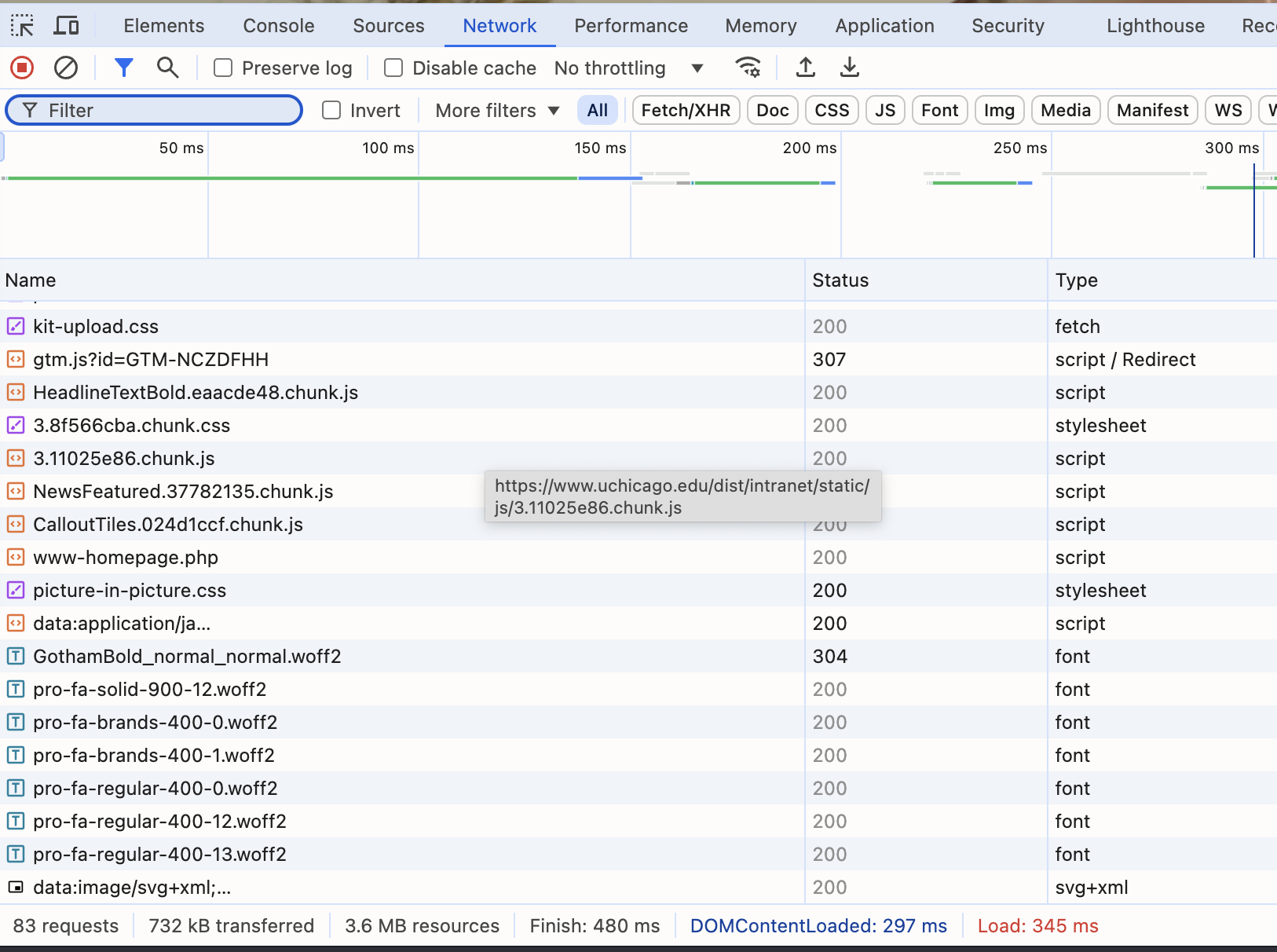
It needs to make dozens of requests very quickly, and so relies on lots of clever tricks like caching, but every time a request is made the page loads all of this data either from the server or your local machine. It then and assembles it into what you are looking at right now, a webpage. The HTML provides the structure and most of the content, the CSS providing styling, and JavaScript for interactivity.
HTML
HTML is a tag-based language, a less-strict variant of XML.
Like XML, HTML documents consist of tags. Tags may contain other tags, or attributes.
<tag-name attrib1="value" attrib2="value">
<inner-tag attrib="100">inner text</inner-tag>
<self-closing-tag attrib="123" />
<!-- HTML comment -->
</tag-name>A typical HTML page might resemble:
<html>
<head>
<link href="styles.css" rel="stylesheet" />
<script type="text/javascript" src="ui.js"></script>
<script type="text/javascript" src="tracking.js"></script>
</head>
<body>
<h1>Title of Page</h1>
<div class="content">
<p>This is some page content.</p>
<a href="/next/">Next Page</a>
</div>
</body>
</html>Tag-based languages like XML and HTML form a tree, where each tag or element forms a node in the tree.
The HTML above would form a tree resembling:
Square nodes represent HTML elements, circular nodes represent text nodes.
<html> & <head>
Generally, there are two kinds of tags: those that provide content & structure to the document, and those that provide metadata to the browser.
The tags <html>, <head>, and <body> will almost always be present.
<html> is the outermost tag, and will typically appear at the beginning of the document. It forms the root of the tree as seen above. There may be a tag or two before this providing context on how the page will be rendered, but for our purposes we’ll consider this the start & end of the document.
<head> is typically the first tag within <html>, it denotes a section that will not appear on the user’s screen. Within this section you often find references to other resources the page will need, such as CSS and JavaScript files in <link>, <style>, and <script> tags.
Since we are focused on getting information out of the page, we’ll often focus on <body>, but it is possible for there to be valuable information in the <head> as well. One example of this would be the <meta> tags that provide information to search engines. These can contain well-formatted data intended for bots populating search engines that would be useful for our own data collection.
The bulk of the page content will be within <body> however.
The common tags that provide information to the browser, and not content for the page itself are:
<html>- the main tag wrapping the HTML document.<head>- an organizational tag used to group metadata at the start of the document.<body>- the body tag itself is an organizational tag, though the contents will be rendered.<link>- provides a link to an outside resource for this page, often a CSS file.<style>- provides inline CSS styling for the page.<meta>- provides page metadata, used by search engines & social media sites.<title>- provides the page title that appears in the browser title bar and bookmarks. (Not on the page!)<script>- contains JavaScript or loads an outside JavaScript resource.
HTML Attributes
As we’ve seen, most tags can contain other tags. They can also contain additional content in the form of attributes.
Attributes are key-value pairs within the tag’s < and >. This element has the attributes id and class: <p id="first" class="generated-text">...</p>.
The most common attributes are id, and class which can be present on any tag.
id is meant to uniquely identify the element, in the above example the <div id="sidebar"> the tag uses the value “sidebar” to identify the purpose of the section of the page. These ids are like variable names, the names are up to you, but helpful/readable names go a long way in making your code readable.
The id does not change anything about how the page looks on its own, but will be used by CSS and/or JavaScript to uniquely identify that element, allowing the page authors to associate custom appearance and/or behaviors.
The class attribute provides a similar purpose, but where id is meant to be unique, class can be used to provide similar styling or behavior to multiple elements.
Some tags, like <a> also define additional attributes with specific meaning. The most common of these would be href as in <a href="link.html">. This creates a link to another page where the destination of the link is the href, while the contents of the tag become the text on the page.
<a href="https://developer.mozilla.org/en-US/docs/Web/HTML/Element/a">this is a link to documentation</a>renders as:
HTML Forms
The final type of tag we’ll discuss here are the tags that make up HTML forms.
These appear within the <body>, but instead of providing page content, typically exist to gather input from the user.
A form on an HTML page might resemble:
<form method="POST">
Enter your username:
<input type="text" name="username" />
<br> <!-- a break tag, creates a newline -->
Enter your password:
<input type="password" name="password1" />
<input type="submit" />
</form>This HTML creates a form:
On submission, the name attributes become keys and user-entered data becomes a value in a key-value pair.
- If the form
methodis POST, these key-value pairs wind up in the HTTP request’s body. - If the method is GET (or omitted), these become part of the URL’s query string.
The form submission would then generate a request resembling:
POST /submit-form HTTP/1.1
Host: example.com
username=steve&password=grasshopperTo which the server could respond, using the response to indicate if the submission was a success (200) or if there was some issue (perhaps a 401 if the user is not authorized).
A common response to a form POST would be a 302 redirect sending the user to the page they were logging in to see.
HTTP/1.1 302 Found
/logged-in-pageIf you are writing a scraper that submits a form, you would issue a GET or POST (depending on the form’s method) with a params or data dictionary resembling the form being filled out.
For example:
httpx.post("https://example.com/submit-form", data={"username": "steve", "password": "grasshopper"})Would mimic the request above.
See httpx.cookies for more information on how you would handle logins in practice.
HTML in Practice
For the first decade or so of the web, most HTML was written by hand.
As a result, browsers are extremely permissive when parsing HTML. Unlike Python where a missing ( would lead to a syntax error, browsers will accept pretty much any HTML and make a best effort to render the page.
A few ways that this manifests:
By convention we write HTML in lower case, but tag and attribute names are case-insensitive. So you may see
<BODY>or<A HREF.HTML also does not generally care about newlines or spaces, in some cases most of the HTML may wind up in a single hard-to-read line:
<html><head><link href="styles.css" rel="stylesheet" />
<script type="text/javascript" src="ui.js"></script><script type="text/javascript" src="tracking.js"></script>
</head><body> <h1>Title of Page</h1><div class="content"><p>This is some page content.</p>
<a href="/next/">Next Page</a></div></body></html>Is the same HTML as in our earlier example, and the changes to formatting would not affect what displays.
- Unclosed tags are sometimes omitted, and the browser can often fill in what’s missing:
For example, the correct form for a table looks like:
<table>
<thead>
<tr> <th>Name</th> <th>Phone</th> </tr>
</thead>
<tbody>
<tr> <td> Mark </td> <td> 123-456-7890 </td> </tr>
<tr> <td> Helly </td> <td> 555-123-0000 </td> </tr>
<tr> <td> Irving </td> <td> 777-999-5555 </td> </tr>
</tbody>
</table>It renders like this:
| Name | Phone |
|---|---|
| Mark | 123-456-7890 |
| Helly | 555-123-0000 |
| Irving | 777-999-5555 |
But this also renders to the same table:
<table>
<tr> <th>Name</th> <th>Phone</th>
<tr> <td> Mark <td> 123-456-7890
<tr> <td> Helly <td> 555-123-0000 </td>
<tr> <td> Irving <td> 777-999-5555
</table>Notice the many missing tags between the two.
- Finally, there are many ways to express the same concepts in HTML, for example, the same data could be represented in completely different markup:
<div class=”datatable”>
<h1>Name</h1>
<h1>Phone</h1>
<div class=”datarow”>
<span id=”c11”>Mark</span>
<span id=”c12”>123-456-7890</span>
</div>
<div class=”datarow”>
<span id=”c21”>Helly</span>
<span id=”c22”>555-123-0000</span>
</div>
<div class=”datarow”>
<span id=”c21”>Irving</span>
<span id=”c22”>777-999-5555</span>
</div>
</div>Web Scraping
Web scraping is the process of extracting structured data from HTML’s semi-structured format.
To do this we will need:
- Parsing. A way to parse HTML text into a tree similar to the one that the browser creates as possible.
- Inspection. To understand where the data we want lives within this tree.
- Extraction. To write code to select just the relevant tags and attributes, and extract their data.
Parsing HTML
Given the chaotic nature of HTML found in the wild, it is best to use a parser that mimics the browser’s rules for handling malformed HTML.
In Python, we have a few options for this. In this course we will use lxml.html.
If you’re curious what other options exist and how they compare, read on. Otherwise you may wish to skip to the lxml.html quickstart.
HTML Parsing Libraries
The three most widely used libraries for parsing are:
BeautifulSoup- The oldest, most features, and slowest. Supports CSS selections & node traversal.lxml.html- Python wrapper for Clibxml2, very fast. Supports XPath & CSS selection as well as node traversal.selectolax- Newest library, gaining some popularity, uses a new HTML parser. Supports CSS & node traversal.
Features
Each library offers a different set of methods to traverse the HTML.
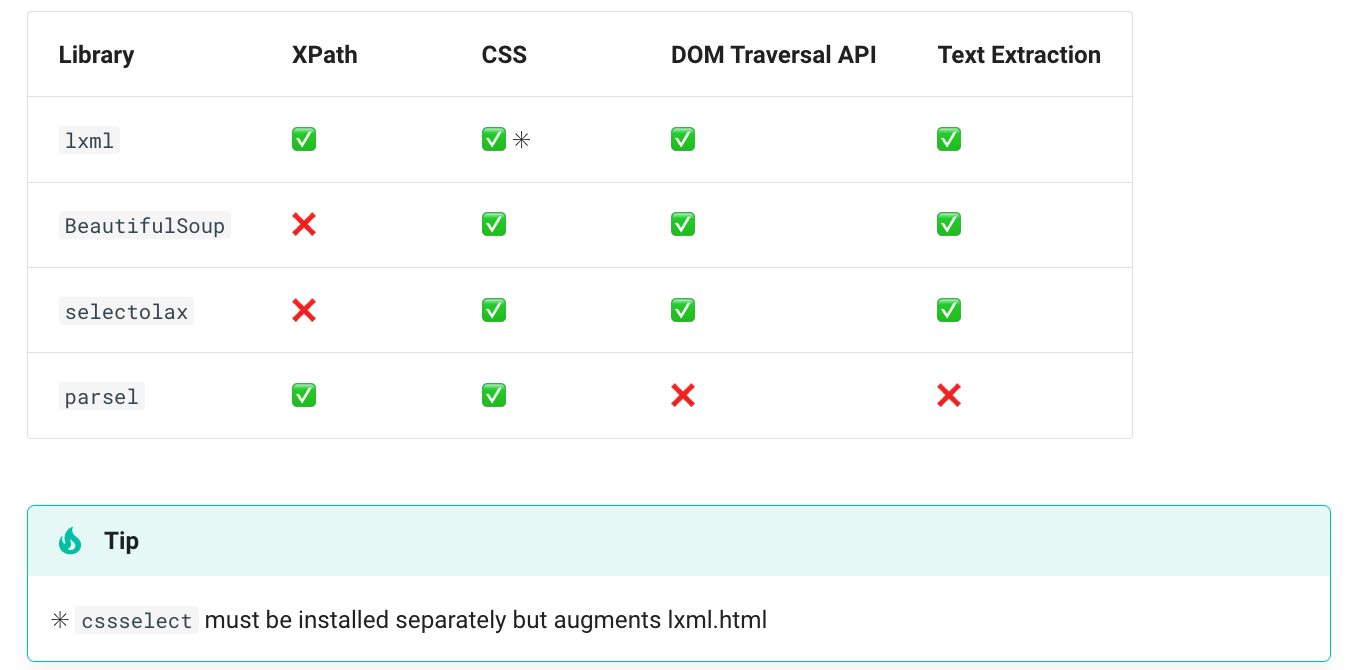
We’ll discuss selectors in the next section, but note that lxml.html with the optional cssselect package offers the widest range of methods to access the data in our page. This means you can use the right tool for the job, without needing to switch libraries.
Parsing Speed
Parsing HTML can be slow, if you are parsing many pages it is important to pick a library that is relatively efficient.
This graph shows how long it takes to load two complex pages (one from Wikipedia and the other from Python.org)
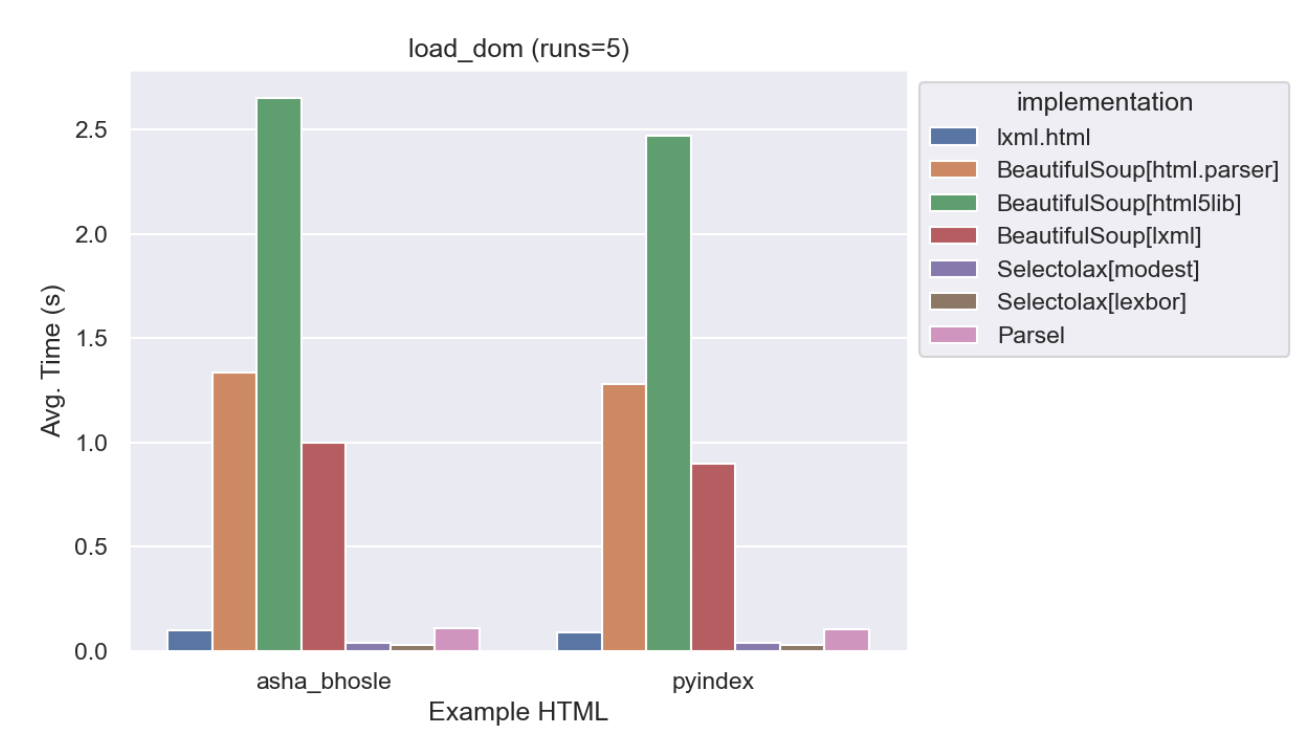
This is the primary reason we don’t use the popular BeautifulSoup library, it is orders of magnitude slower than the others.
lxml.html quickstart
Whichever library you are using, the first thing you will need to do is convert the HTML string into a parsed tree.
For lxml.html that means using lxml.html.fromstring(html_text) where html_text is a string with the actual HTML in it.
If you are using httpx this might look like:
import httpx
import lxml.html
resp = httpx.get("https://example.com")
# error-checking omitted for example
root = lxml.html.fromstring(resp.text)
print(type(root), "\n", root)<class 'lxml.html.HtmlElement'>
<Element html at 0x124589e90>The result is of type HtmlElement, this represents a node in the tree.
Once we have the root node of the parsed HTML, we can call methods to get related nodes.
Common lxml.html methods:
| method | purpose |
|---|---|
elem = lxml.html.fromstring(html_text) |
Parse html_text to obtain a root node elem |
elem.getchildren() |
Get list of all immediate child elements. |
elem.parent |
Get direct parent of node. |
elem.get_element_by_id("some_id") |
Get element that matches ID |
elem.cssselect("p.name") |
Use CSS selectors to obtain all <p> tags with class name. |
elem.xpath("//p[@class='name']") |
Use XPath selector to obtain same as above. |
elem.text_content() |
Get all interior text (includes text of subnodes). |
elem.get("href") |
Get href attribute value from the node. |
lxml.html handles both the parsing (fromstring) as well as the extraction.
Extraction
Once we have parsed the data with fromstring, we will write code that navigates this tree.
The table above shows the most useful methods, some like getchildren(), and .parent allow you to navigate the tree one node at a time.
If you had a page with a structure like:
<!-- most HTML ommitted to focus on relevant path -->
<html>
<head></head>
<body>
<div class="main-content">
<table>
<tbody>
<tr>
<td>
Mark
</td>
</tr>
<tr>
<td>
Helly
</td>
</tr>
</tbody>
</table>
</div>
</body>
</html>You’d wind up with code that resembled:
# html > body > div > table > tbody > tr > td
root.getchildren()[1].getchildren()[0].getchildren()[0].getchildren()[1].getchildren()[0].text_content()As you might imagine, this code is excessively fragile. If new elements are added to the page, one of the getchildren()[0] calls might need to become getchildren[2]
Debugging/maintaining such code is a nightmare– so we’ll typically use selectors which help us navigate the table more efficiently and robustly.
You’ll see a few methods in the table above that allow you to select elements based on their properties:
elem.get_element_by_id("some_id")elem.cssselect("p.name")elem.xpath("//p[@class='name']")
The first of these is the simplest, we said that the id attribute in HTML is meant to be unique. If we are lucky, and the HTML in question puts an id on or near the item we are attempting to extract.
We can also use the cssselect and/or xpath attributes, which support miniature query languages which allow you to select a more specific element or set of elements based on their tag names, positions, and other attributes.
We’ll see examples of those, and you will also learn more about them in the Appendix on Selectors for a guide to CSS & XPath selector syntax.
Scraping Example
To demonstrate the usage of these tools, let’s look at a real world page: https://www.senate.gov/senators/SenateSalariesSince1789.htm
Once we’re on this page, we will use some tools built in to every browser:
- View Source - View the HTML returned by the current page’s main response. Can be accessed via:
- Right Click, (Developer Tools), View Page Source
- changing the URL in the browser toolbar to
view-source:https://example.com
- Web Inspector - Part of the built in Developer Tools, opened via:
- Menu bar: Tools -> Developer Tools
- Right Click, (Developer Tools), Inspect
- Cmd-Opt-I on MacOS
- Ctrl-Shift-I or F12 on Windows
Browse to this page, view the source, and then look for the text “$6.00 per diem”, which is in the first row of the table we’re interested in.
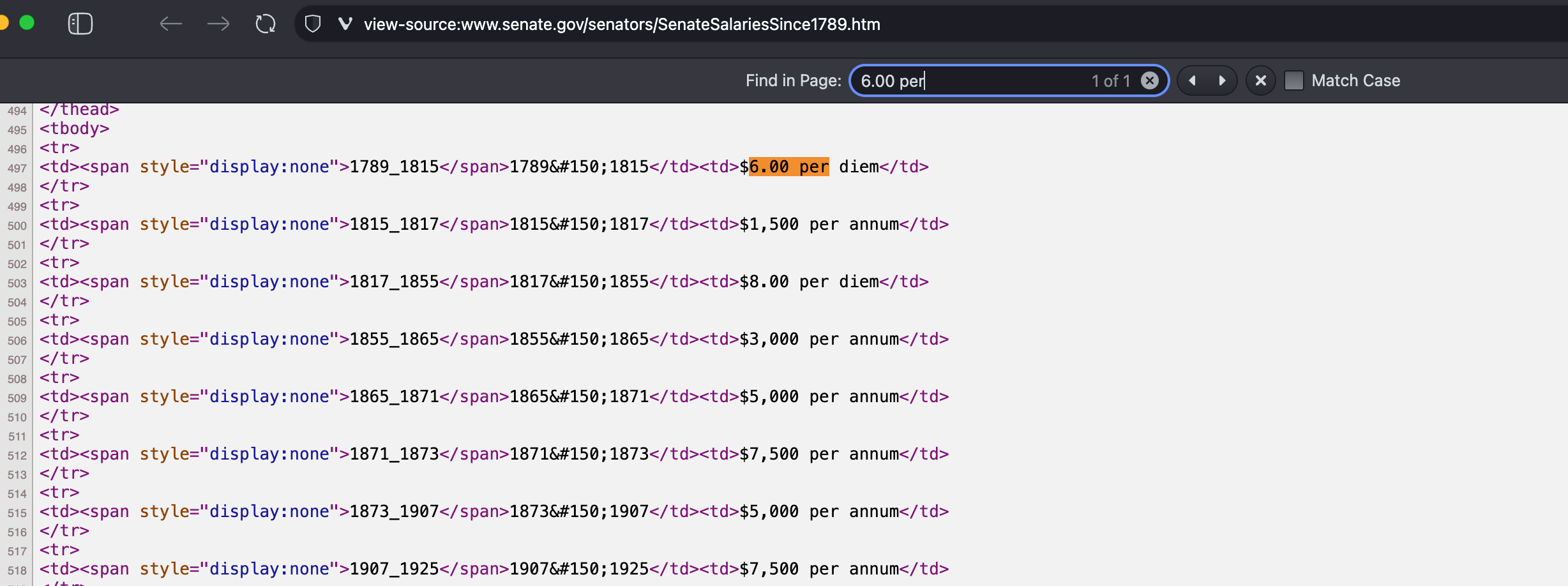
We can then identify the relevant HTML. We aim to identify the smallest containing element, which here would be the <table>.
<table width="100%" id="SortableData_table" cellspacing="0">
<tfoot class="SortableData_table_header1">
<tr><th style="border:0;" colspan="2"></th></tr>
</tfoot>
<thead class="SortableData_table_header2">
<tr align="left">
<th align="left" style="width:">Years</th><th align="left" style="width:">Salary</th>
</tr>
</thead>
<tbody>
<tr>
<td><span style="display:none">1789_1815</span>1789–1815</td><td>$6.00 per diem</td>
</tr>
...
</tbody>
</table># demo_traversal.py
import httpx
import lxml.html
# first we'll fetch the HTML in question and load it with lxml
response = httpx.get("https://www.senate.gov/senators/SenateSalariesSince1789.htm")
root = lxml.html.fromstring(response.text)
print(root) <Element html at 0x12458a070># we can examine the root node and see 3 children
print(root.getchildren())[<!-- <![endif] -->, <Element head at 0x12458b740>, <Element body at 0x12458b790>]# but it'll be more reliable to jump straight to the table by ID
table = root.get_element_by_id("SortableData_table")
print("Children of table:", table.getchildren())
print("Rows: ", table.getchildren()[2].getchildren())Children of table: [<Element tfoot at 0x121e1c770>, <Element thead at 0x123c02a70>, <Element tbody at 0x12458ad40>]
Rows: [<Element tr at 0x121e1c770>, <Element tr at 0x123c02a70>, <Element tr at 0x12458ad40>, <Element tr at 0x12458b3d0>, <Element tr at 0x12458ae80>, <Element tr at 0x12458b920>, <Element tr at 0x1245bc180>, <Element tr at 0x1245bc220>, <Element tr at 0x1245bc2c0>, <Element tr at 0x1245bc310>, <Element tr at 0x1245bc360>, <Element tr at 0x1245bc3b0>, <Element tr at 0x1245bc400>, <Element tr at 0x1245bc450>, <Element tr at 0x1245bc4a0>, <Element tr at 0x1245bc4f0>, <Element tr at 0x1245bc540>, <Element tr at 0x1245bc590>, <Element tr at 0x1245bc5e0>, <Element tr at 0x1245bc630>, <Element tr at 0x1245bc680>, <Element tr at 0x1245bc6d0>, <Element tr at 0x1245bc720>, <Element tr at 0x1245bc770>, <Element tr at 0x1245bc7c0>, <Element tr at 0x1245bc810>, <Element tr at 0x1245bc860>, <Element tr at 0x1245bc8b0>, <Element tr at 0x1245bc900>, <Element tr at 0x1245bc950>, <Element tr at 0x1245bc9a0>, <Element tr at 0x1245bc9f0>, <Element tr at 0x1245bca40>, <Element tr at 0x1245bca90>, <Element tr at 0x1245bcae0>, <Element tr at 0x1245bcb30>, <Element tr at 0x1245bcb80>, <Element tr at 0x1245bcbd0>, <Element tr at 0x1245bcc20>, <Element tr at 0x1245bcc70>, <Element tr at 0x1245bccc0>, <Element tr at 0x1245bcd10>, <Element tr at 0x1245bcd60>, <Element tr at 0x1245bcdb0>, <Element tr at 0x1245bce00>, <Element tr at 0x1245bce50>, <Element tr at 0x1245bcea0>, <Element tr at 0x1245bcef0>, <Element tr at 0x1245bcf40>, <Element tr at 0x1245bcf90>, <Element tr at 0x1245bcfe0>, <Element tr at 0x1245bd030>, <Element tr at 0x1245bd080>, <Element tr at 0x1245bd0d0>, <Element tr at 0x1245bd120>, <Element tr at 0x1245bd170>, <Element tr at 0x1245bd1c0>, <Element tr at 0x1245bd210>, <Element tr at 0x1245bd260>, <Element tr at 0x1245bd2b0>, <Element tr at 0x1245bd300>]# demo_css.py
# Ideally, we would rely less on getchildren() since a change to the
# structure would break our scraper.
# Here we use a CSS Selector:
#
# #SortableData_table -- the # character looks up by ID
# tbody tr -- names without a leading # or . refer to tag names
#
# So this grabs "all tr elements that are inside the tbody
# that are inside id=SortableData_table".
rows = root.cssselect("#SortableData_table tbody tr")
for row in rows:
# this time we'll iterate over the <td> elements within
# since we are starting the .cssselect with `row` instead of `root`
# this only gets the <td>s within the current row
year_td, salary_td = row.cssselect("td")
# finally, we use .text_content() to extract the text nodes
# which contain the data we're after
year = year_td.text_content()
salary = salary_td.text_content()
print(year, "|", salary)1789_181517891815 | $6.00 per diem
1815_181718151817 | $1,500 per annum
1817_185518171855 | $8.00 per diem
1855_186518551865 | $3,000 per annum
1865_187118651871 | $5,000 per annum
1871_187318711873 | $7,500 per annum
1873_190718731907 | $5,000 per annum
1907_192519071925 | $7,500 per annum
1925_193219251932 | $10,000 per annum
1932_193319321933 | $9,000 per annum
1933_193519331935 | $8,500 per annum
1935_194719351947 | $10,000 per annum
1947_195519471955 | $12,500 per annum
1955_196519551965 | $22,500 per annum
1965_196919651969 | $30,000 per annum
1969_197519691975 | $42,500 per annum
1975_197719751977 | $44,600 per annum
1977_197819771978 | $57,500 per annum
1979_198319791983 | $60,662.50 per annum
19831983 | $69,800 per annum
19841984 | $72,600 per annum
1985_198619851986 | $75,100 per annum
19870101_19870203Jan 1, 1987 Feb 3, 1987 | $77,400 per annum
19870204Feb 4, 1987 | $89,500 per annum
19900201Feb 1, 1990 | $98,400 per annum
19911991 | $101,900 per annum
19910815Aug 15, 1991 | $125,100 per annum
19921992 | $129,500 per annum
19931993 | $133,600 per annum
19941994 | $133,600 per annum
19951995 | $133,600 per annum
19961996 | $133,600 per annum
19971997 | $133,600 per annum
19981998 | $136,700 per annum
19991999 | $136,700 per annum
20002000 | $141,300 per annum
20012001 | $145,100 per annum
20022002 | $150,000 per annum
20032003 | $154,700 per annum
20042004 | $158,100 per annum
20052005 | $162,100 per annum
20062006 | $165,200 per annum
20072007 | $165,200 per annum
20082008 | $169,300 per annum
20092009 | $174,000 per annum
20102010 | $174,000 per annum
20112011 | $174,000 per annum
20122012 | $174,000 per annum
20132013 | $174,000 per annum
20142014 | $174,000 per annum
20152015 | $174,000 per annum
20162016 | $174,000 per annum
20172017 | $174,000 per annum
20182018 | $174,000 per annum
20192019 | $174,000 per annum
20202020 | $174,000 per annum
20212021 | $174,000 per annum
20222022 | $174,000 per annum
20232023 | $174,000 per annum
20242024 | $174,000 per annum
20252025 | $174,000 per annum# demo_xpath.py
# Finally, we'll do the same using XPath syntax.
# The concepts are the same, but we use different syntax
# // -- // means "anywhere on page"
# table[@id='SortableData_table'] -- table[@id=...] grabs all tables with that id
# /tbody/tr -- like the above example, filters children of the selected table
rows = root.xpath("//table[@id='SortableData_table']/tbody/tr")
for row in rows:
# like above, we start our query now on the row in question (not root)
# and use Xpath's directory-like syntax to get the underlying text
year_td, salary_td = row.xpath(".//td")
year = year_td.text_content()
salary = salary_td.text_content()
print(year, "|", salary)1789_181517891815 | $6.00 per diem
1815_181718151817 | $1,500 per annum
1817_185518171855 | $8.00 per diem
1855_186518551865 | $3,000 per annum
1865_187118651871 | $5,000 per annum
1871_187318711873 | $7,500 per annum
1873_190718731907 | $5,000 per annum
1907_192519071925 | $7,500 per annum
1925_193219251932 | $10,000 per annum
1932_193319321933 | $9,000 per annum
1933_193519331935 | $8,500 per annum
1935_194719351947 | $10,000 per annum
1947_195519471955 | $12,500 per annum
1955_196519551965 | $22,500 per annum
1965_196919651969 | $30,000 per annum
1969_197519691975 | $42,500 per annum
1975_197719751977 | $44,600 per annum
1977_197819771978 | $57,500 per annum
1979_198319791983 | $60,662.50 per annum
19831983 | $69,800 per annum
19841984 | $72,600 per annum
1985_198619851986 | $75,100 per annum
19870101_19870203Jan 1, 1987 Feb 3, 1987 | $77,400 per annum
19870204Feb 4, 1987 | $89,500 per annum
19900201Feb 1, 1990 | $98,400 per annum
19911991 | $101,900 per annum
19910815Aug 15, 1991 | $125,100 per annum
19921992 | $129,500 per annum
19931993 | $133,600 per annum
19941994 | $133,600 per annum
19951995 | $133,600 per annum
19961996 | $133,600 per annum
19971997 | $133,600 per annum
19981998 | $136,700 per annum
19991999 | $136,700 per annum
20002000 | $141,300 per annum
20012001 | $145,100 per annum
20022002 | $150,000 per annum
20032003 | $154,700 per annum
20042004 | $158,100 per annum
20052005 | $162,100 per annum
20062006 | $165,200 per annum
20072007 | $165,200 per annum
20082008 | $169,300 per annum
20092009 | $174,000 per annum
20102010 | $174,000 per annum
20112011 | $174,000 per annum
20122012 | $174,000 per annum
20132013 | $174,000 per annum
20142014 | $174,000 per annum
20152015 | $174,000 per annum
20162016 | $174,000 per annum
20172017 | $174,000 per annum
20182018 | $174,000 per annum
20192019 | $174,000 per annum
20202020 | $174,000 per annum
20212021 | $174,000 per annum
20222022 | $174,000 per annum
20232023 | $174,000 per annum
20242024 | $174,000 per annum
20252025 | $174,000 per annumWeb Scraping Algorithm
The steps above form the “web scraping algorithm” you will follow for any given page:
- Inspect the page via view-source or your web inspector.
- Find a CSS (or XPath) selector to select an element containing the data you want. Aim to start with an element as close to the element in question as you can.
- Traverse the tree as necessary using other CSS/XPath expressions or node traversal if needed to get sub-elements.
- Repeat for other types of data that you need.
Still look for opportunities to write helper functions and convenience methods, for example if you are selecting data from nearly-identical structures, you can often write a function that takes a selector & reuses the sub-element traversal.
Scraping Best Practices
Writing web scrapers is often a bit different from the code you’re used to. This is in part because of the way that your scrapers rely on the data that they are scraping, which is out of your control.
It’s always good to strive for clean & readable code, but if you are dealing with messy HTML with lots of edge cases, your code might be similarly messy.
Comment liberally! Especially assumptions about the page structure.
Above we had the code:
year_td, salary_td = row.xpath(".//td")It would break if there were a third <td>. That’s not only OK, it’s desirable.
If we saw a third column in our code, it would take manual verification to learn if the new column was added at the beginning, middle, or end.
So while this code looks more robust:
# the first two columns are year & salary
tds = row.xpath(".//td")
year_td = td[0]
salary_td = td[1]If they added a new column at the start of the table, that would now be td[0], with the others shifted forward.
This is why it is good to have code that breaks if the relevant page section changes.
On the other hand, if an unrelated part of the page changes, perhaps they add a new <table> with a different ID– we do not want our code to break.
If we were using getchildren() all the way down the tree, that would break if almost any change happened to the HTML.
So, trying to make your scraper never break should not be the goal. You’d wind up needing to anticipate a nearly infinite number of potential changes and in fact makes your code more likely to produce bad data in the future.
Instead the goal is to not break unless the relevant part(s) of the page change.
- Tip #1: Avoid depending (unnecessarily) on ordering of tags.
- Tip #2: Try to just use selectors from the immediate path.
- Tip #3: Comment assumptions liberally!
As we saw, you can’t plan for every scenario, often better to take a fail-fast approach when something differs from what you expect.
- Tip #4: Check expected number of children if a known number.
- Tip #5: Add soundness checks for data w/ known constraints. (e.g. years, phone numbers)
class UnexpectedDataError(Exception):
pass
# at time of writing, the first two columns are year & salary
tds = row.xpath(".//td")
if len(tds) != 2:
raise UnexpectedDataError("saw more than two columns in salary table!")
year_td = td[0]
salary_td = td[1]Scraping: Common Challenges
Once you get the hang of extracting data from HTML, the whole web can be a source of data.
That said, there are some common roadblocks you will run into that might cause trouble:
Malformed HTML
As we’ve seen HTML can be quite messy/broken and still work in the browser. Sometimes this leads to our code and the browser parsing it differently, and data that is found on the page is not easily found with your library of choice.
This usually manifests as an expected branch of the tree missing. Perhaps they made a mistake in the <body> tag, omitting the closing >. This may mean there is no body tag in the parsed tree returned by lxml.html. In the browser you may still see the page working as expected.
Remedy
If you can find the error in question, let’s say a missing > you could manipulate the string before passing it to lxml.html.fromstring or equivalent.
Remember, the input to that function is a string, so you may find yourself with code like:
resp = httpx.get(url)
# as of 2025-01-01 there was a bug in the HTML
# this replaces the broken tag with one that will work
fixed_text = resp.text.replace("<body ", "<body> ")
root = lxml.html.fromstring(fixed_text)Missing Content in HTML
You are looking at a page and can see the text you’d like to extract, perhaps a table row with the word “January”.
When you look at the HTML you are getting back from the response, you can’t find that word at all– and you confirm it isn’t an issue with the parser (see above) by checking if "January" in response.text – and find that it isn’t anywhere in the response!
This means that the text in question is likely coming in one of the dozens of additional responses the page makes, in this case it is most likely loading additional data via JavaScript.
To confirm this, you can also compare the source you see when you View Source to that of the Web Inspector:
- View Source will give you back the data returned in the initial response.
- The Web Inspector is a live-updating reflection of the page’s source code, so if something has updated it since initial load you’d see it there.
Remedies
There’s no singular solution to this– you will need to learn more about how the page in question works, a process known as reverse engineering.
If you are lucky, the page is using an API behind the scenes, and you may be able to use the inspector to identify that API and use it yourself, bypassing the HTML.
If not, you sometimes need to rely on tools like playwright that let you automate the browser itself.
Why not just always automate the browser?
Tools like playwright (and selenium before that) are primarily for testing web applications. They can interact with the browser as a side-effect of their intended purpose, and have proven quite useful for scrapers.
The overhead however of using a browser is significant, scrapers written with these tools are often an order of magnitude or two more memory intensive, and often significantly slower.
For that reason, we typically use them as a last resort, only when the page is JavaScript-laden or has other measures that make a browser necessary
Different HTML in browser vs. Python
In the course of investigating your issue you may discover that Python is in fact getting different HTML than the browser.
This would be clear if you looked at the code via View Source and saw “January”, but it was nowhere to be found in the code you fetched in Python.
This is because there’s some difference in the two requests:
- Perhaps the server sees your user agent as
python/httpxand doesn’t serve the same page it would to a browser with a proper User-Agent. - Or maybe in the browser you are logged in, and therefore your request is sending cookies/headers that are not present in your code.
The fix here is to make sure that your request is as similar to the one the browser is making as possible. Using the browser tools to view headers is usually the first place to start, it will even let you copy the headers out in a JSON dictionary that you could use to replicate the exact request the browser is making.
Anti-Bot CDNs
Finally, some sites actively discourage scraping. You may find that you get different HTML as in the above case, but no matter what you try you keep getting a different page.
Typically this page will actually include a message:

For our purposes, if this happens we stop there. A site actively preventing scraping is out of scope for this course, and comes with a whole set of legal questions should you circumvent it.
Real World Data Sources
Legality & Ethics
This raises an important point, web scraping is generally recognized as legal in the US1. If you are mimicking what a browser would do, and obtaining content that you have permission to obtain otherwise, you are generally in the clear. The same way that you could copy & paste the information into an Excel file, creating a CSV automatically is considered the same.
A few general guidelines to keep in mind:
- Circumventing security measures, no matter how trivial, may be illegal. The Computer Fraud and Abuse Act is problematically broad. This is a grey area and should be approached with caution.2
- Regardless of the means of collection, the legality often comes down to usage. If you are violating copyright, it does not matter how the data was collected.
- U.S. Government data is in the public domain, and as such if it is online it is fair game.
- Further, under US law, data cannot itself subject to copyright3. A collection of facts is non-copyrightable under US law.
- This is not true in the European Union, and many other jurisdictions which do recognize a database right.
- Which brings us to an important point – these rules are not true worldwide! Foreign government data licenses can & will vary– do your research!
- No matter the source, do not circumvent rate limits or other similar measures! Be a good neighbor.
If in doubt, ask! I’ve dealt with dozens upon dozens of scrapers, dealt with more than a handful of spurious legal threats, and glad to provide guidance if you have doubts.
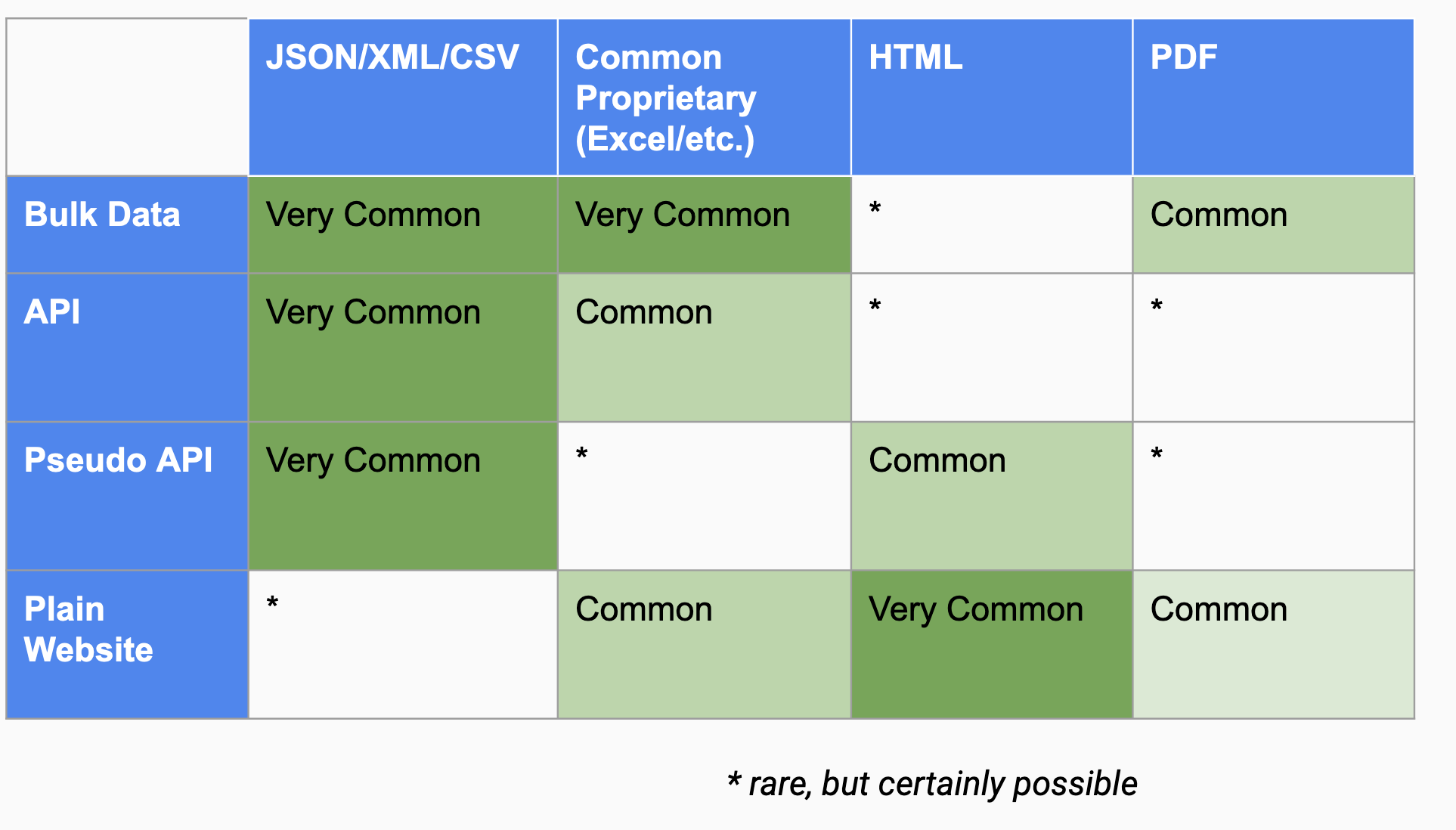
Bulk data vs. API vs. Scraping?
Compared to scraping, an API is almost always preferable. Compared to the temperamental nature of scrapers, writing code against an API means a reliable & stable interface. Even if the source releases new updates to their API that break your code, it is typically much easier to fix code that depends on a pre-defined structure like JSON than the wild west of HTML.
This also applies to the “psuedo-APIs” that you discover when inspecting web traffic and see that they are populating a page with JSON or some other known format. Take advantage of any structured data that you find!
But what if they offer both an API and bulk data. Perhaps a zip of JSON or CSV files containing all of the records from the past year.
The first consideration will be how much of the data you need.
If you need all of the data, or close to all of it– bulk data is often your best bet. Using an API (or scraping) is more time consuming and limiting when you factor in the required time.sleep calls.
Even if you plan to use the API to get regular updates, you may find it is beneficial to use bulk data to explore & understand the data.
Bulk Data, best for:
- data exploration
- offline processing
- typically fastest to work with
- often not as up-to-date as an API
- e.g. Election Results that are not changing
API, best for:
- selecting subsets of larger data set
- incremental updates & timeliness
- most up-to-date data
- e.g. Weather, where you don’t need the whole planet/history of the climate, just a useful sliver
Further Exploration
Mozilla Developer Network, MDN, is the most reliable & trustworthy resource for learning web languages like HTML and CSS.
HTML
If you’re not familiar with HTML, it may help to read:
If you’re already familiar with HTML and just want a refresher, you might benefit from the HTML Elements page.
Selectors
The better you become with CSS and/or XPath selectors, the stronger your scraper skills will be.
- As an overview, you can start with the Appendix on Selectors for a guide to CSS & XPath selector syntax.
You may also benefit from:
Web Scraping Libraries
These are third-party libraries that help perform common tasks related to web scraping:
- playwright - A browser automation library, allows more advanced scraping techniques including bypassing bot detection.
- scrapy - Popular, very large, web scraping framework for Python. Good for very large scraping projects.
- scrapelib - Library that provides some commonly used helpers for web scraping: retries and caching.
- spatula - Object-oriented page-based web scraping library for Python.
(I wrote the latter two as part of Open States project.)
https://www.reuters.com/legal/litigation/anti-hacking-law-does-not-bar-data-scraping-public-websites-9th-circuit-2022-04-19/↩︎
Aaron Swartz for example was prosecuted not for scraping data, but for the alleged circumvention of a security measure. https://en.wikipedia.org/wiki/United_States_v._Swartz↩︎
https://en.wikipedia.org/wiki/Database_right#United%20States↩︎